




NVFP4 实现 16 位训练精度,4 位训练速度和效率
近年来,AI工作负载呈指数级增长,这不仅体现在大型语言模型(LLM)的广泛部署上,也反映在预训练和后训练阶段对处理更多token的迫切需求。随着企业不断扩大计算基础设施规模,以训练和部署拥有数十亿参数的基础模型,维持更高的token吞吐量已成为一项关键任务。未来的进步不仅取决于效率的提升,更取决于AI工厂能够处理的token数量——这正是解锁下一代模型能力的关键所在。 AI优化的数据格式已成为该领域的关键创新。NVIDIA推出的NVFP4是一种专为实现卓越推理延迟、吞吐量和能效而设计的4位格式,可在保持生产级精度的同时显著提升性能,窄精度计算正由此深刻改变着推理领域。 如今,NVIDIA 将这一创新延伸至预训练阶段,标志着大语言模型(LLM)开发迈出了重要一步。采用 NVFP4 进行预训练,不仅显著提升了大规模 LLM 训练的效率,也大幅优化了整体基础设施的利用率。这并非一次简单的渐进式改

AIGC 算力提升:多维度协同优化路径
AIGC(生成式人工智能)的算力需求随模型规模(如千亿参数大模型)、生成任务复杂度(如图像高清生成、长文本创作)呈指数级增长,单纯依赖硬件堆叠难以高效满足需求。算力提升需从硬件升级、算法优化、软件框架、系统架构、数据处理五大维度协同推进,实现 “算力密度提升” 与 “算力利用率优化” 双重目标。 一、硬件层:算力基础的 “扩容与增效” 硬件是 AIGC 算力的物理载体,核心方向是通过 “专用化芯片设计”“存储 – 计算协同”“集群架构优化” 突破算力瓶颈。 1. 专用芯片:从 “通用” 到 “定制化” 的算力聚焦 传统 CPU 因并行计算能力弱,难以支撑 AIGC 大规模矩阵运算(如 Transformer 模型的自注意力机制),专用芯片成为核心选择: 2. 存储 – 计算协同:解决 “数据搬运瓶颈” AIGC 计算中,数据在内存、显存间的传输延迟(“内存

新研究揭示开源AI模型安全风险:若脱离限制运行或将被黑客劫持
IT之家 1 月 30 日消息,路透社 1 月 29 日援引一项最新研究称,开源大语言模型若脱离主流平台的护栏与限制,在外部计算机上运行,就可能成为黑客与犯罪分子轻易劫持的目标,带来新的安全漏洞与风险。 研究人员表示,攻击者可以直接针对运行大语言模型的主机下手,随后操控模型生成垃圾信息、编写钓鱼内容、发动虚假信息宣传,从而绕开大型平台原有的安全机制。 这项研究由 SentinelOne 与 Censys 两家网络安全公司历时 293 天联合完成,并独家提供给路透社,揭示了数千个开源大语言模型部署背后潜在的非法用途规模。研究人员称,风险场景涵盖黑客攻击、仇恨言论与骚扰、暴力血腥内容生成、个人数据窃取、诈骗与欺诈,甚至在个别情况下还涉及儿童性虐待材料。 研究人员指出,开源大语言模型变体数量庞大,互联网上可访问的运行实例中,相当一部分来自 Meta 的 Llama、谷歌 DeepMind 的 G
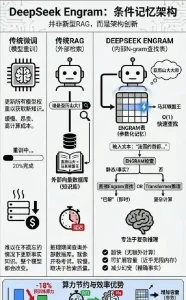
DeepSeek震撼登场:v4代码实力能否碾压GPT与Claude?下月揭晓!
创新,总是从一个看似微小的火花开始。多年前,我第一次读到彼得·德鲁克那句“有效的创新始于小处”,并没太在意。直到最近看到 DeepSeek 的故事,才体会到这句话的分量。那种“以一己之力打破旧秩序”的勇气,就像黑夜里的一束光,照亮了整个行业的路径。 我依然记得 2025 年春节那场令全球震撼的“DeepSeek 周”。当时大家还沉浸在节日气氛中,这家公司却突然发布了 DeepSeek R1。一夜之间,它登上了全球应用商店的榜首,让硅谷的工程师们彻夜难眠。那一刻,我第一次看到“中国 AI 反超”的真实画面。甚至连美国科技股都应声震荡,足见它带来的冲击。 如今一年过去,2026 年的春节又将来临。坊间传得沸沸扬扬——DeepSeek v4 要登场了。这一次,它不只是想做一款更聪明的模型,而是要拿下最具含金量的战场——代码生成。有人戏称,这是一场“程序员的巅峰对决”,对手不止是 OpenAI,还

PyTorch 简介
PyTorch 是一个开源的 Python 机器学习库,基于 Torch 库,底层由 C++ 实现,应用于人工智能领域,如计算机视觉和自然语言处理。 PyTorch 最初由 Meta Platforms 的人工智能研究团队开发,现在属 于Linux 基金会的一部分。 许多深度学习软件都是基于 PyTorch 构建的,包括特斯拉自动驾驶、Uber 的 Pyro、Hugging Face 的 Transformers、 PyTorch Lightning 和 Catalyst。 PyTorch 主要有两大特征: PyTorch 包括 torch.autograd、torch.nn、torch.optim 等子模块。 PyTorch 包含多种损失函数,包括 MSE(均方误差 = L2 范数)、交叉熵损失和负熵似然损失(对分类器有用)等。 PyTorch 特性 动态计算图(Dynamic Comp
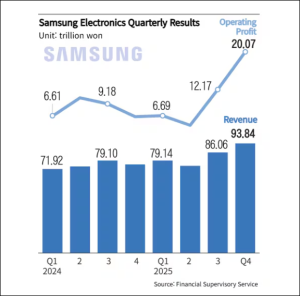
三星去年营收1.62万亿元,HBM订单今年已全部订满
日前,三星电子递交了一份“历史最强”季度营收报告:季度营收和营业利润双双创下纪录,半导体业务的利润更飙升超400%。 据韩国《朝鲜日报》、彭博社等外媒消息,1月29日,三星电子正式公布其2025年第四季度及全年业绩。第四季度单季,三星营收同比增23.8%,达到93.84万亿韩元(当前汇率约合人民币4570亿元);营业利润飙升209.2%,达到20.07万亿韩元(约合人民币977亿元),大幅刷新了公司在2018年第三季度创下的17.6万亿韩元的纪录。 去年全年,三星年营收增长10.87%,达到333.6万亿韩元(约合人民币1.62万亿元);年营业利润增长33.3%,达到43.6万亿韩元(约合人民币2123亿元)。 从不同业务划分来看,2025年第四季度,备受关注的半导体业务营收增长46.2%,达到44万亿韩元(约合人民币2145亿元),而营业利润猛增465%,达到16.4万亿韩元(约合人民币