
创新,总是从一个看似微小的火花开始。多年前,我第一次读到彼得·德鲁克那句“有效的创新始于小处”,并没太在意。直到最近看到 DeepSeek 的故事,才体会到这句话的分量。那种“以一己之力打破旧秩序”的勇气,就像黑夜里的一束光,照亮了整个行业的路径。
我依然记得 2025 年春节那场令全球震撼的“DeepSeek 周”。当时大家还沉浸在节日气氛中,这家公司却突然发布了 DeepSeek R1。一夜之间,它登上了全球应用商店的榜首,让硅谷的工程师们彻夜难眠。那一刻,我第一次看到“中国 AI 反超”的真实画面。甚至连美国科技股都应声震荡,足见它带来的冲击。
如今一年过去,2026 年的春节又将来临。坊间传得沸沸扬扬——DeepSeek v4 要登场了。这一次,它不只是想做一款更聪明的模型,而是要拿下最具含金量的战场——代码生成。有人戏称,这是一场“程序员的巅峰对决”,对手不止是 OpenAI,还有 Anthropic。与此同时,GPT5.3 也在备战,一场算法与算力的正面对撞即将上演。

据传,DeepSeek v4 在内部基准测试中展现出了“越级挑战”的姿态,甚至让一些硅谷研究者直呼“背脊发凉”。在 HumanEval 这种衡量编程智能的权威测试中,它的表现堪称惊艳。更令人期待的是,它将同时发布两个版本,还附带一个深度集成的 AI 开发工具。换句话说,AI 不再只是窗口中的聊天对象,而将真正嵌入开发者的工作流,成为生产力的一部分。
技术细节方面,DeepSeek v4 的三大核心创新堪称“算法战力三件套”。

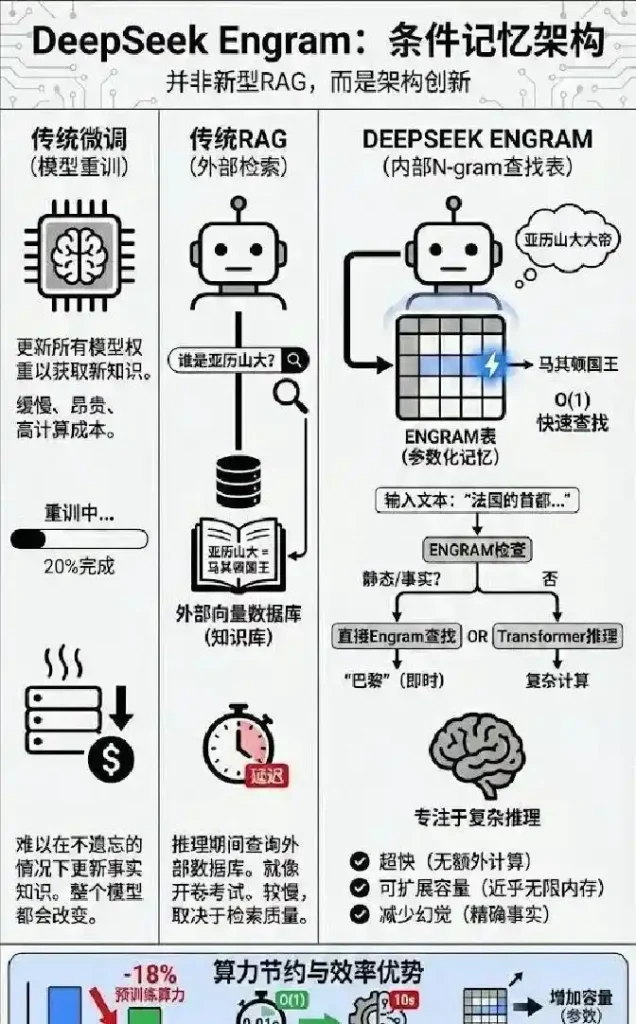
第一,是 Engram 架构。简单理解,它就像在大脑外开辟了一座“记忆仓”,让知识与计算各司其职。传统模型常常为了检索事实大动干戈,浪费大量显存;而 Engram 创新地将知识存在廉价的 CPU 内存中,让昂贵的 GPU 只做高价值的逻辑推理。25% 的参数负责“记忆”,75% 负责“思考”,这让模型既聪明又高效。
第二,是 mHC 架构。这是一种颠覆传统拓扑结构的尝试。十多年来,“残差连接”一直是神经网络的基石,而 DeepSeek 竟然敢彻底重写这条规则。mHC 架构像是蜂群作战,既保证能量守恒,又实现了极端稳定。即使网络堆叠到数百层,也不会出现信号衰减或训练崩溃。有人形容,这像是一支纪律严明的“算法空军”,每一架无人机都精确执行飞行任务。

第三,是 R1 的强化学习体系。它教会模型“慢思考”,就像人类通过反思变得更聪明。DeepSeek 在早期版本中验证了“能力蒸馏”的可行性——即使小模型,也能继承大模型的推理智慧。这一突破,意味着更节能、更普惠的智能。
纵观 AI 的发展路线,我们看到两种信仰:一种是 OpenAI 连年扩容的“暴力美学”,另一种是 DeepSeek 的“算法优雅”。面对算力封锁与硬件劣势,它没有抱怨,也没有盲目跟随,而是像工匠一样重塑底层。DeepSeek 的工程哲学或许可以用一句话概括——“既然造不出重型卡车,那就造一万辆摩托车去挑战高速。”

在这样的精神下,mHC 架构成为一种奇迹。它让模型在算力有限的约束中逆袭,让更多中小企业能参与 AI 创造的浪潮。尤其当 DeepSeek v4 宣布将完全开源,这不仅是一款产品,更是一种信念——创新应该被共享,智能应该属于每一个人。
有人说,DeepSeek 打破了“创新者的窘境”,我更愿意说它给了世界一记当头棒喝:当所有人都在堆参数、拼显卡时,总要有人敢去拆掉传统,重新定义可能。从舍弃老旧架构到提出 Engram 与 mHC,这家中国公司正为全球 AI 效率革命贡献新的答案。
创新,从不是运气的游戏,而是一种厚积薄发的笃定。DeepSeek 向世界展示了,真正伟大的创新者,不是去追随旧范式,而是敢于推倒它。
下个月,这位“算法战士”又将踏上战场。故事会怎样发展?也许无人能断言。但可以肯定的是——AI 世界的格局,正被改写。
那么,你如何看待 DeepSeek 的崛起?在这场全球科技角力中,你更期待谁的未来?欢迎在评论区留下你的看法。
来源:百度百家号-四秩光阴守素简

