

NVFP4 实现 16 位训练精度,4 位训练速度和效率
近年来,AI工作负载呈指数级增长,这不仅体现在大型语言模型(LLM)的广泛部署上,也反映在预训练和后训练阶段对处理更多token的迫切需求。随着企业不断扩大计算基础设施规模,以训练和部署拥有数十亿参数的基础模型,维持更高的token吞吐量已成为一项关键任务。未来的进步不仅取决于效率的提升,更取决于AI工厂能够处理的token数量——这正是解锁下一代模型能力的关键所在。
AI优化的数据格式已成为该领域的关键创新。NVIDIA推出的NVFP4是一种专为实现卓越推理延迟、吞吐量和能效而设计的4位格式,可在保持生产级精度的同时显著提升性能,窄精度计算正由此深刻改变着推理领域。
如今,NVIDIA 将这一创新延伸至预训练阶段,标志着大语言模型(LLM)开发迈出了重要一步。采用 NVFP4 进行预训练,不仅显著提升了大规模 LLM 训练的效率,也大幅优化了整体基础设施的利用率。这并非一次简单的渐进式改进,而是一次对大规模模型训练方式的根本性变革。
在 AI 工厂时代,计算是推动进步的核心引擎,精度也不再仅仅是后端的技术细节,而成为关键的战略优势。NVFP4 4 位预训练技术重新定义了效率与可扩展性的边界,为高性能 AI 模型的开发树立了全新标准。
NVFP4 训练目前仍处于研究阶段,旨在探索并验证 4 位精度在大型模型预训练中的潜力。NVIDIA 正与亚马逊云科技、Cohere、谷歌云、Kimi AI、微软 AI、OpenAI、Perplexity、Reflection 和 Runway 等领先机构积极开展合作,共同推进 NVFP4 的相关研究。
什么是 4 位量化?
4 位量化是指将模型的权重和激活值从典型的 16 位或 32 位浮点精度降低至 4 位,从而大幅减少计算精度。
使用4位进行预训练具有挑战性,因为在提升整体训练速度的同时,必须谨慎处理梯度和参数更新,以保持模型的准确性。此外,将高精度张量映射到更小的量化值集合时,还需采用专门的技术和方法,以确保模型的有效性。
更少的位数如何为 AI 工厂解锁更多功能?
近年来,AI工作负载呈指数级增长,不仅体现在大型语言模型(LLM)的部署上,也反映在基础模型的预训练与后训练规模不断扩大。随着企业持续扩展计算基础设施以应对数十亿参数模型的训练和部署需求,AI工厂能够支持的 token 吞吐量正逐渐成为衡量其能力进步的关键指标,决定着新功能的实现与突破。
推理技术已历经多轮创新,从 FP32、FP16 发展到 FP8,再到近期 NVIDIA 发布的用于 AI 推理的 NVFP4。尽管 后训练量化(PTQ) 等方法已证明,NVFP4 能在保持模型精度的同时显著提升推理吞吐量,但预训练阶段仍面临挑战,因为基础模型在训练过程中仍依赖 BF16 或 FP8 以确保稳定性和收敛性。
训练是AI工厂中消耗大量计算资源、电力和时间的核心环节。在电力预算固定且GPU算力稀缺的情况下,开发者必须精打细算,关注每一个比特、每一个token以及每一个epoch的使用。吞吐量不再是一个抽象的指标,而是直接决定了模型的规模上限、实验的迭代次数,以及技术突破的速度。
这正是4位精度发挥变革性作用的关键所在。通过降低内存需求、提升算术吞吐量并优化通信效率,4位精度预训练使AI工厂能够在相同硬件条件下处理更多token。借助恰当的量化方案,它不仅能实现与FP8/BF16相当的精度,还能显著提升吞吐量,从而加快模型收敛速度,增加每个计算单元可执行的实验次数,并推动模型规模扩展至前所未有的前沿水平。换句话说,减少位数不仅节省了成本,更拓展了AI工厂所能实现的成就边界。
用于预训练的 NVFP4 量化配方
为实现4位精度的预训练,我们开发了一套专门的NVFP4预训练方案,有效应对大规模训练中面临的动态范围、梯度波动和数值稳定性等核心挑战。
Blackwell 是 NVIDIA 首个原生支持 FP4 格式的架构。凭借 GB200 和 GB300 上强大的 FP4 计算吞吐能力,该架构能够加速低精度矩阵运算,同时保持大规模模型训练所需的精度、规模与并行性,从而实现高效的 4 位训练。这使其成为下一代 AI 工厂部署基于 FP4 的预训练任务的理想选择。
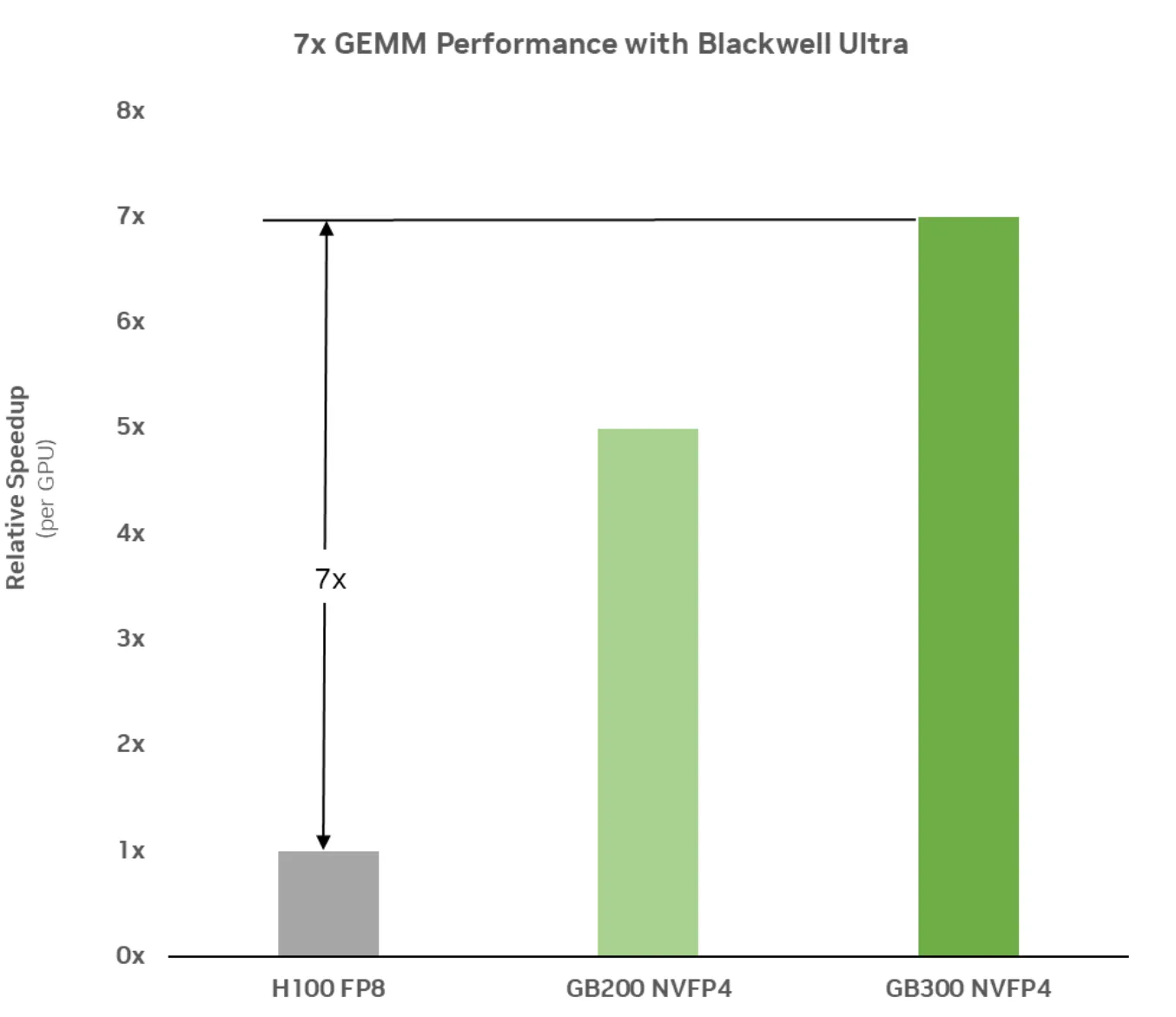
下图1展示了使用Blackwell Ultra测得的GEMM性能,结果显示,相较于Hopper架构,性能提升了7倍。现代大语言模型(LLM)的核心计算主要依赖于矩阵乘法,尤其是在全连接层或线性层中。因此,这类操作的执行效率至关重要。通过采用FP4精度实现更快速、更高效的矩阵运算,GEMM性能的提升意味着整个预训练过程——从前向传播到梯度更新——都能显著加速,从而大幅缩短训练时间,并推动大规模模型的快速开发。
为实现高效的窄精度训练,NVIDIA 的 NVFP4 预训练方案采用了多种关键技术,这些技术均基于性能与准确性的综合考量进行选择。
- 通过 NVFP4 的微块扩展增强价值表示: Blackwell 架构引入了对 NVFP4 的原生 Tensor Core 支持。NVFP4 是一种用于权重和激活的 4 位数值格式,采用微块缩放技术,即每组 16 个 4 位元素共享一个统一的缩放因子。相比 MXFP4 中 32 个元素的块大小,NVFP4 将块大小减半至 16 个元素,从而有效降低异常值的影响,实现更精细的缩放。这种更细粒度的控制有助于减少量化误差,提升模型的整体精度。
- NVFP4 采用高精度块编码,并引入 E4M3 格式的比例因子:比例因子的精度在量化质量和准确性方面起着关键作用。与仅支持 2 的幂次作为缩放因子(E8M0)、且易产生较大舍入误差的 MXFP4 不同,NVFP4 使用具有额外尾数位的 E4M3 高精度比例因子,能够实现更精细的缩放,更充分地利用有限的量化区间,并更准确地表示块内的数值。
- 在大语言模型(LLM)预训练过程中,梯度和激活值常出现较大的离群值,这可能对低精度量化造成不利影响。 通过在GEMM操作的输入上应用哈达玛变换,可以重塑其分布,使其更接近高斯分布,从而有效缓解异常值的影响,提升张量在低精度表示下的准确性。这类变换对模型架构完全透明,可无缝集成到线性层的前向传播和反向传播过程中。
- 为确保训练的稳定性与高效性:我们采用量化技术以保持前向与反向传播过程的一致性。 通过应用选择性2D块级量化等方法,能够在整个训练过程中维持张量表示的稳定性。这种一致性对于最大限度减少信号失真、改善收敛行为并提升模型整体鲁棒性至关重要,尤其是在使用NVFP4等低精度格式时。
- 通过随机舍入减少偏差:与传统的确定性舍入不同,随机舍入会根据数值在两个可表示值之间距离的比例,以相应的概率随机地将梯度向上或向下舍入。这一机制对于减轻舍入偏差、在训练过程中保持梯度的流动性,以及最终提升模型的准确性至关重要。

NVFP4 实现 4 位预训练:万亿级 Token 的准确性和稳定性
为确保窄精度格式在大规模预训练中切实可行,必须保障模型的准确性与收敛稳定性。为此,我们评估了4位精度在大型模型训练中的可行性,基于与 NVIDIA Nemotron Nano 2 相似的120亿参数Mamba-Transformer混合架构模型(12B Hybrid Mamba-Transformer),开展了针对FP8和NVFP4精度格式的实验。该模型采用分阶段数据混合方法,在包含10万亿token的海量数据集上进行训练,并在预训练的第二阶段和第三阶段分别切换至70%和90%的不同数据集组合。
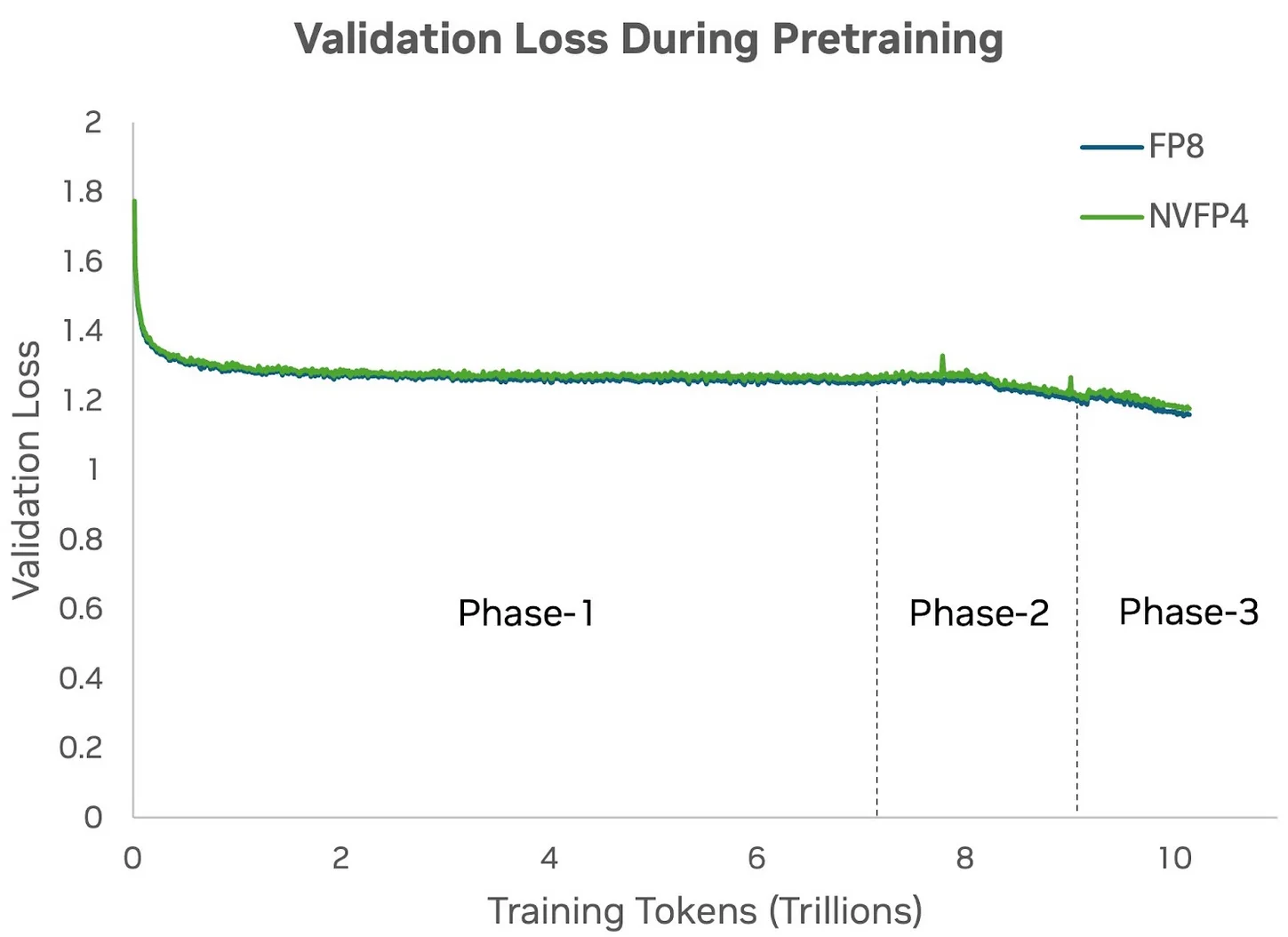
12B Hybrid Mamba-Transformer 模型的初始版本是使用 8 位精度(FP8)进行训练的。先前的研究表明,FP8 的训练效果与 16 位精度非常接近,因此我们将其作为基准进行对比。在此基础上,我们成功地使用 NVFP4 精度从头开始完成了该 12B 模型的训练,验证了这一新型低精度格式能够支持万亿级 token 的完整预训练过程。NVFP4 在训练中表现出稳定的收敛性,未出现超低精度训练中常见的不稳定或发散问题。
下图3显示,NVFP4的验证损失曲线在整个训练过程中与更高精度基准(即FP8)的损失曲线非常接近。这表明,上述量化技术能够有效保持模型的训练动态,即使在显著降低位宽的情况下,4位预训练的动态特性仍与高精度训练结果高度相似。
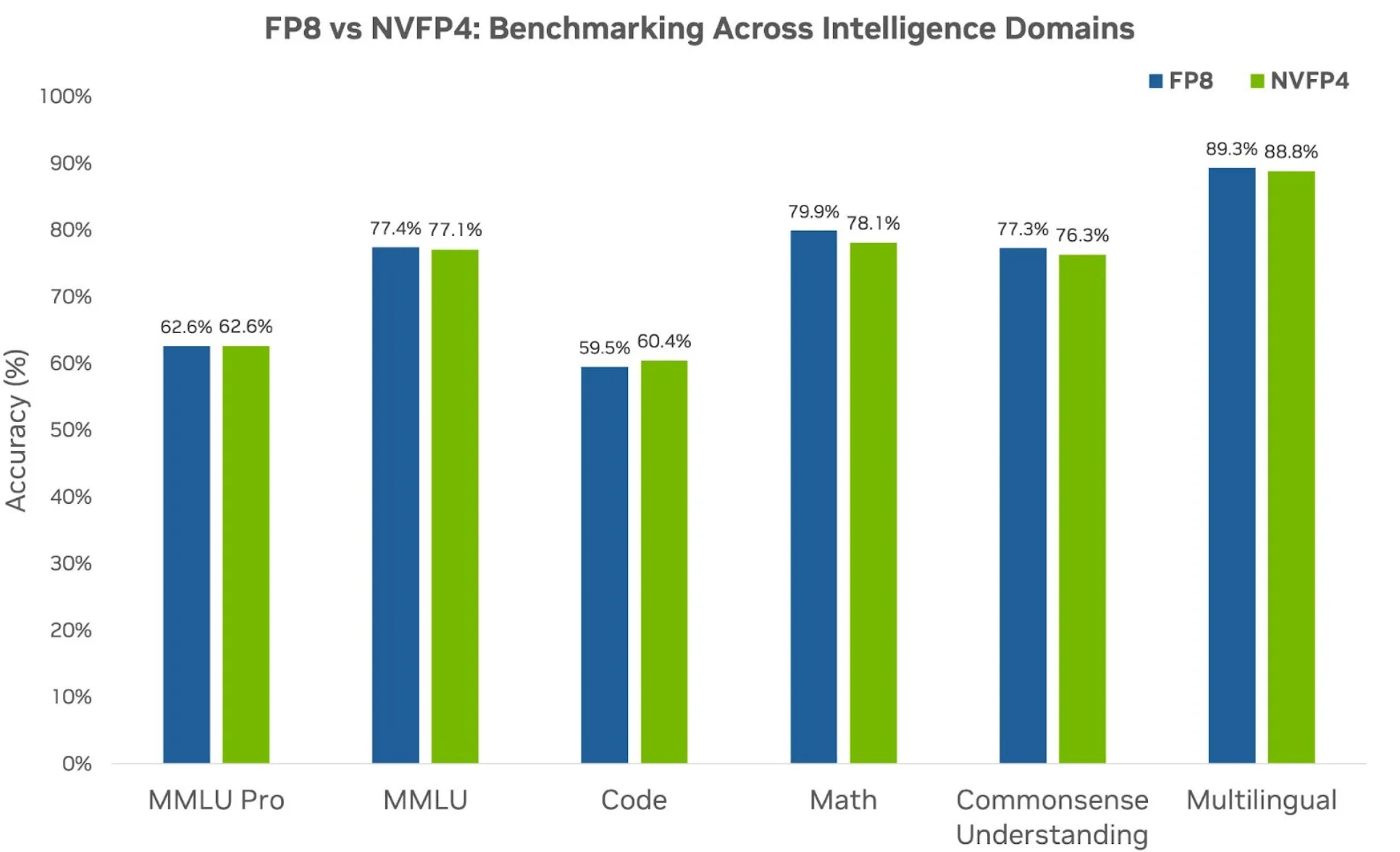
然后,我们使用 NVFP4 对一个 12B 规模的混合 Mamba-Transformer 模型进行了预训练,并将其与更高精度的 FP8 基线进行对比,以评估其在多种下游任务及智能领域中的表现。如图 4 所示,NVFP4 在所有领域均达到了与 FP8 相当的性能,充分体现了其有效性。这一结果进一步验证了最初的假设:即使在万亿级 token 的大规模训练场景下,NVFP4 仍是预训练大语言模型的可靠选择,展现出其在高效训练前沿大规模模型方面的巨大潜力。
训练更智能,而不仅仅是更努力
NVIDIA 的 NVFP4 格式正在重塑 AI 训练领域,为速度、效率以及有目标的创新树立了全新标杆。通过支持 4 位精度预训练,NVFP4 使 AI 工厂能够更快速、更可持续地扩展,为生成式 AI 的下一个发展阶段铺平道路。作为一项持续演进的前沿技术,NVFP4 不断为开发先进模型的团队创造新机遇,推动高性能与高能效 AI 的进步。4 位预训练在计算效率上实现了重大突破,不仅为更复杂的架构、更大规模的训练任务和更多 token 的处理开辟了可能,也为智能系统的未来发展注入了强劲动力。
实际使用中,在物理支持fp4的架构面世前,通过fp8单元运算fp4,会浪费掉一倍的显存容量,所以这种技术的出现,为大参数量中低精度的模型训练和推理提供了一个很好的选择。
来源:英伟达开发者论坛 作者:Kirthi Devleker and Farshad Ghodsian

AIGC 算力提升:多维度协同优化路径
AIGC(生成式人工智能)的算力需求随模型规模(如千亿参数大模型)、生成任务复杂度(如图像高清生成、长文本创作)呈指数级增长,单纯依赖硬件堆叠难以高效满足需求。算力提升需从硬件升级、算法优化、软件框架、系统架构、数据处理五大维度协同推进,实现 “算力密度提升” 与 “算力利用率优化” 双重目标。
一、硬件层:算力基础的 “扩容与增效”
硬件是 AIGC 算力的物理载体,核心方向是通过 “专用化芯片设计”“存储 – 计算协同”“集群架构优化” 突破算力瓶颈。
1. 专用芯片:从 “通用” 到 “定制化” 的算力聚焦
传统 CPU 因并行计算能力弱,难以支撑 AIGC 大规模矩阵运算(如 Transformer 模型的自注意力机制),专用芯片成为核心选择:
- GPU(图形处理器):当前 AIGC 主流算力载体,凭借海量 CUDA 核心(或 AMD 的 ROCm 核心)支持高效并行计算,适合模型训练与推理。例如英伟达 H100 GPU 的 Tensor Core 可提供 4PFlops 的 FP8 精度算力,较前代 A100 提升 3 倍以上,能显著加速 Stable Diffusion、GPT 类模型的生成速度。
- ASIC(专用集成电路):为 AIGC 场景定制电路,能效比远超 GPU。例如谷歌 TPU v5e,针对 Transformer 模型优化,算力密度达 500 TOPS/W,适合云端大规模推理;国内华为昇腾 910B、壁仞 BR100 等 ASIC 芯片,通过自研架构(如昇腾的 Da Vinci 架构)提升大模型训练效率。
- FPGA(现场可编程门阵列):兼具灵活性与高效性,可根据 AIGC 任务动态调整硬件逻辑,适合中小规模模型的推理场景(如边缘端 AIGC 生成),代表产品如赛灵思 Alveo 系列。
2. 存储 – 计算协同:解决 “数据搬运瓶颈”
AIGC 计算中,数据在内存、显存间的传输延迟(“内存墙” 问题)常导致 GPU 算力闲置。存储 – 计算协同技术通过 “靠近计算单元部署存储” 减少数据搬运:
- 存算一体芯片:将存储单元(如 DRAM、NAND)与计算单元集成,直接在存储内部完成数据运算,避免数据传输损耗。例如美光的存算一体 AI 芯片,针对 AIGC 推理场景,能效比提升 10 倍以上。
- 高带宽存储(HBM):为 GPU 配备堆叠式 HBM 显存(如 HBM3),带宽较传统 GDDR6 提升 3-4 倍(HBM3 带宽达 1TB/s 以上),可支撑千亿参数模型的参数加载与中间数据存储,减少 “算力等数据” 的闲置时间。
3. 集群架构:从 “单卡” 到 “分布式扩展”
单芯片算力有限,通过集群化部署实现算力叠加:
- 异构计算集群:融合 GPU、ASIC、CPU 等多种芯片,按任务类型分配算力(如 GPU 负责训练、ASIC 负责推理)。例如阿里云 “飞天智算平台” 采用 GPU+FPGA 异构架构,支持万卡级集群,可承载 GPT-4 级模型的训练。
- 高速互联技术:通过 NVLink、PCIe 5.0、RDMA(远程直接内存访问)等技术实现集群内芯片间低延迟通信。例如英伟达 DGX SuperPOD 集群,通过 NVLink Switch 实现 8 块 H100 GPU 间的高速互联,通信延迟低于 1 微秒,保障分布式训练的效率。
二、算法层:用 “智能设计” 降低算力消耗
算法优化是 “以少胜多” 的核心 —— 通过改进模型结构、减少冗余计算,在不增加硬件成本的前提下提升算力利用效率,是 AIGC 算力提升的 “软核心”。
1. 模型压缩:在 “精度损失可控” 下减小计算量
通过削减模型冗余参数或降低计算精度,实现 “轻量型” 算力需求:
- 量化(Quantization):将模型参数从高精度(如 FP32、FP16)转为低精度(如 INT8、INT4,甚至 FP8),减少计算量与内存占用。例如 GPT-3 模型经 INT8 量化后,显存占用降低 75%,推理速度提升 3 倍,且生成文本质量损失小于 5%;英伟达 TensorRT 工具可自动完成量化优化,适配 AIGC 推理场景。
- 剪枝(Pruning):移除模型中 “贡献度低” 的参数(如权重接近 0 的神经元),保留核心结构。例如 ResNet 网络经剪枝后,参数数量减少 60%,但图像生成精度仅下降 2%,适合边缘端 AIGC 应用(如手机端 AI 绘画)。
- 蒸馏(Knowledge Distillation):用 “大模型(教师模型)” 的知识训练 “小模型(学生模型)”,让小模型具备接近大模型的生成能力。例如用 1750 亿参数的 GPT-3 作为教师模型,蒸馏出 10 亿参数的学生模型,推理算力需求降低 90%,可部署于普通服务器。
2. 高效模型架构:从 “冗余设计” 到 “算力友好”
优化模型结构(尤其是 Transformer 架构),减少不必要的计算步骤:
- 稀疏注意力(Sparse Attention):传统 Transformer 的自注意力机制需计算 “所有 token 间的关联”(复杂度 O (n²)),稀疏注意力仅计算 “关键 token 关联”(如局部窗口内、或基于内容匹配的 token),复杂度降至 O (n)。例如谷歌的 Sparse Transformer、OpenAI 的 FlashAttention,可将长文本生成(如 1 万字小说)的算力需求降低 50% 以上。
- 分层架构(Layer-wise Design):针对 AIGC 任务的 “粗细粒度需求”,设计分层模型。例如图像生成时,先通过轻量层生成低分辨率图像,再通过高精度层优化细节,而非全程用高算力模型;百度文心一言的 “分层推理” 架构,可根据文本长度动态调用不同层数的 Transformer,短文本推理算力降低 40%。
3. 动态计算策略:按需分配算力
根据生成任务的实时需求,动态调整算力投入,避免 “算力浪费”:
- 自适应精度(Adaptive Precision):训练时用高精度(如 FP32)保障模型收敛,推理时用低精度(如 INT8)提升速度;生成关键内容(如文本的核心观点、图像的主体元素)时用高算力,生成背景或辅助内容时用低算力。
- 早停机制(Early Stopping):在模型生成过程中,若已满足质量要求(如文本通顺度、图像清晰度达标),则提前终止计算。例如 AI 绘画工具 MidJourney 的 “动态迭代终止” 功能,平均减少 20% 的迭代次数,算力消耗降低 15%。
三、软件与框架层:打通 “硬件 – 算法” 的算力通道
软件框架是连接硬件算力与 AIGC 算法的 “桥梁”,优化框架可减少 “算力损耗”,让硬件性能充分释放。
1. 深度学习框架优化:算子级效率提升
优化框架中的核心计算单元(算子),减少冗余调用与数据传输:
- 算子融合(Operator Fusion):将多个独立算子(如卷积、激活、批归一化)合并为一个 “融合算子”,减少算子间的数据传输开销。例如 PyTorch 的 TorchScript、TensorFlow 的 XLA 编译器,可自动完成算子融合,AIGC 模型训练速度提升 20%-30%。
- 定制化算子开发:针对 AIGC 核心算子(如 Transformer 的自注意力算子、扩散模型的采样算子),开发硬件友好的定制算子。例如英伟达为 Stable Diffusion 开发的 “Diffusion 算子库”,将图像生成速度提升 2 倍;国内 MindSpore 框架的 “AI 算子自动生成工具”,可针对昇腾芯片优化算子,算力利用率提升至 90% 以上。
2. 并行计算框架:最大化集群算力利用率
通过 “多维度并行” 策略,将大模型任务拆解到多个硬件节点,避免单节点算力瓶颈:
- 数据并行(Data Parallelism):将训练数据拆分到多个 GPU,每个 GPU 训练部分数据,再同步参数。适合模型较小、数据量较大的场景(如 AIGC 图像预训练),主流框架如 Horovod、PyTorch DDP(Distributed Data Parallel)。
- 模型并行(Model Parallelism):将大模型的不同层拆分到多个 GPU,每个 GPU 负责部分层的计算。例如 GPT-3 的 1750 亿参数模型,通过模型并行拆到 1024 块 GPU 上,解决单卡显存不足问题,代表工具如 Megatron-LM。
- 流水线并行(Pipeline Parallelism):将模型训练流程拆分为 “数据加载 – 计算 – 参数更新” 等阶段,不同 GPU 并行处理不同阶段,减少空闲时间。例如谷歌的 GPipe 框架,可将 Transformer 模型训练速度提升 3 倍。
四、系统与架构层:全局算力的 “调度与协同”
通过优化算力调度、云边端协同等系统级设计,提升整体算力利用效率,避免 “算力闲置” 或 “资源错配”。
1. 智能算力调度:让算力 “按需分配”
通过调度系统动态分配硬件资源,匹配 AIGC 任务的算力需求:
- 任务优先级调度:将高优先级任务(如大模型紧急训练)分配给高算力节点,低优先级任务(如小规模推理)分配给闲置资源。例如阿里云的 “Volcano 调度系统”,可实现 GPU 资源利用率从 50% 提升至 80% 以上。
- 分时复用(Time Sharing):同一硬件节点在不同时间段处理不同任务(如白天处理推理、夜间处理训练),避免算力闲置。例如腾讯云的 “AIGC 算力池”,通过分时复用将 GPU 利用率提升至 90%。
2. 云边端协同:分层承载算力需求
将 AIGC 任务按 “算力强度” 拆分到云端、边缘端、终端,实现 “算力分级承载”:
- 云端:承载大模型训练(如 GPT-4、文心一言的预训练)、大规模推理(如百万用户同时使用的 AI 写作工具),依赖大规模 GPU/ASIC 集群。初步实施可使用线上云服务器:如“智算云扉https://waas.aigate.cc/productService、算吧 https://www.suanba.cc/index”等租赁平台,支持按量计费。
- 边缘端:承载中等规模推理(如园区内的 AI 视频生成、门店的 AI 设计工具),使用边缘服务器(如搭载 4-8 块 GPU 的边缘节点),减少云端传输延迟。
- 终端:承载轻量级 AIGC 任务(如手机端 AI 贴纸生成、PC 端短文本改写),依赖终端芯片(如苹果 A17 Pro 的神经网络引擎、高通骁龙 8 Gen3 的 NPU),通过模型压缩适配终端算力。
五、数据层:减少 “算力空转” 的源头优化
AIGC 计算中,数据预处理(如图像裁剪、文本分词)和数据传输的延迟常导致 GPU “空等数据”,优化数据处理可间接提升算力利用率。
1. 并行数据预处理:避免 “算力等数据”
通过并行化工具加速数据预处理,让数据供给速度匹配 GPU 计算速度:
- 专用预处理框架:使用 DALI(NVIDIA Data Loading Library)、TF Data(TensorFlow Data)等工具,通过 CPU 多线程并行处理数据(如图像解码、归一化、增强),预处理速度提升 3-5 倍,避免 GPU 闲置。
- 数据预缓存(Pre-caching):将高频使用的训练数据(如 AIGC 图像数据集)提前缓存到高速存储(如 SSD、内存),减少从硬盘读取数据的延迟。
2. 数据传输优化:减少 “数据在路上” 的时间
通过高速传输协议与压缩技术,降低数据在 “存储 – 内存 – GPU” 间的传输延迟:
- RDMA(远程直接内存访问):跳过 CPU 直接在存储与 GPU 显存间传输数据,传输延迟降低至微秒级,适合分布式训练中的数据同步。
- 数据压缩:对预处理后的数据(如文本 token、图像特征)进行轻量级压缩(如 LZ4、Snappy 算法),减少传输数据量,提升传输速度。
总结:AIGC 算力提升的核心逻辑
AIGC 算力提升并非单一维度的 “硬件堆砌”,而是 **“硬件筑基 + 算法提效 + 软件搭桥 + 系统调度 + 数据优化” 的协同工程 **:
- 硬件是 “基础”:通过专用芯片、存算协同、集群扩展提升算力上限;
- 算法是 “关键”:通过模型压缩、架构优化减少算力需求,实现 “降本增效”;
- 软件与系统是 “保障”:打通硬件与算法的通道,优化资源分配,避免算力浪费。
未来,随着量子计算(如量子 AI 芯片)、脑启发计算(如类脑芯片)等新兴技术的发展,AIGC 算力提升将迎来 “范式突破”,进一步支撑更复杂的生成任务(如实时 3D 场景生成、多模态长内容创作)。
来源:智算云扉(知乎)

新研究揭示开源AI模型安全风险:若脱离限制运行或将被黑客劫持
IT之家 1 月 30 日消息,路透社 1 月 29 日援引一项最新研究称,开源大语言模型若脱离主流平台的护栏与限制,在外部计算机上运行,就可能成为黑客与犯罪分子轻易劫持的目标,带来新的安全漏洞与风险。
研究人员表示,攻击者可以直接针对运行大语言模型的主机下手,随后操控模型生成垃圾信息、编写钓鱼内容、发动虚假信息宣传,从而绕开大型平台原有的安全机制。
这项研究由 SentinelOne 与 Censys 两家网络安全公司历时 293 天联合完成,并独家提供给路透社,揭示了数千个开源大语言模型部署背后潜在的非法用途规模。研究人员称,风险场景涵盖黑客攻击、仇恨言论与骚扰、暴力血腥内容生成、个人数据窃取、诈骗与欺诈,甚至在个别情况下还涉及儿童性虐待材料。
研究人员指出,开源大语言模型变体数量庞大,互联网上可访问的运行实例中,相当一部分来自 Meta 的 Llama、谷歌 DeepMind 的 Gemma 等主流模型的衍生版本。IT之家从报道中获悉,部分开源模型自带护栏,研究仍发现数百起护栏被明确移除的情况。
SentinelOne 情报与安全研究执行主任 Juan Andres Guerrero-Saade 强调,行业对于安全控制的讨论正在“忽略一种明显存在的剩余能力”,开源算力正在被用于各种用途,其中既有合法用途,也有明显的犯罪用途。Guerrero-Saade 把这种现象比作一座尚未被行业与开源社区充分纳入视野的“冰山”。
研究团队重点分析了通过 Ollama 部署、对公众开放访问的开源大语言模型实例。Ollama 是一种工具,个人或机构可在本地运行不同模型的自有版本。
研究人员在约四分之一的观察对象中能够读取系统提示词,也就是决定模型行为的核心指令。在这些可见提示词中,7.5% 被判断可能会为有害行为提供支持。
全球人工智能治理中心 CEO 兼创始人 Rachel Adams 在邮件中表示,开放模型一旦发布,责任就不再只属于单一主体,而是生态系统共同承担,包括最初发布模型的实验室。实验室不可能对所有下游滥用负责,因为这些行为很难提前预料,但实验室仍负有重要的注意义务,需要预判可预见风险、记录危害,并提供缓解工具与指导,尤其是在全球执法能力不均衡的背景下。